Extract data from any website in seconds
One-click data extraction from any webpage. AI auto-detects products, jobs, listings, and tables. Handles pagination, infinite scroll, and detail pages. Export to CSV, XLSX, JSON, or Google Sheets. No coding, no accounts, no limits — completely free.
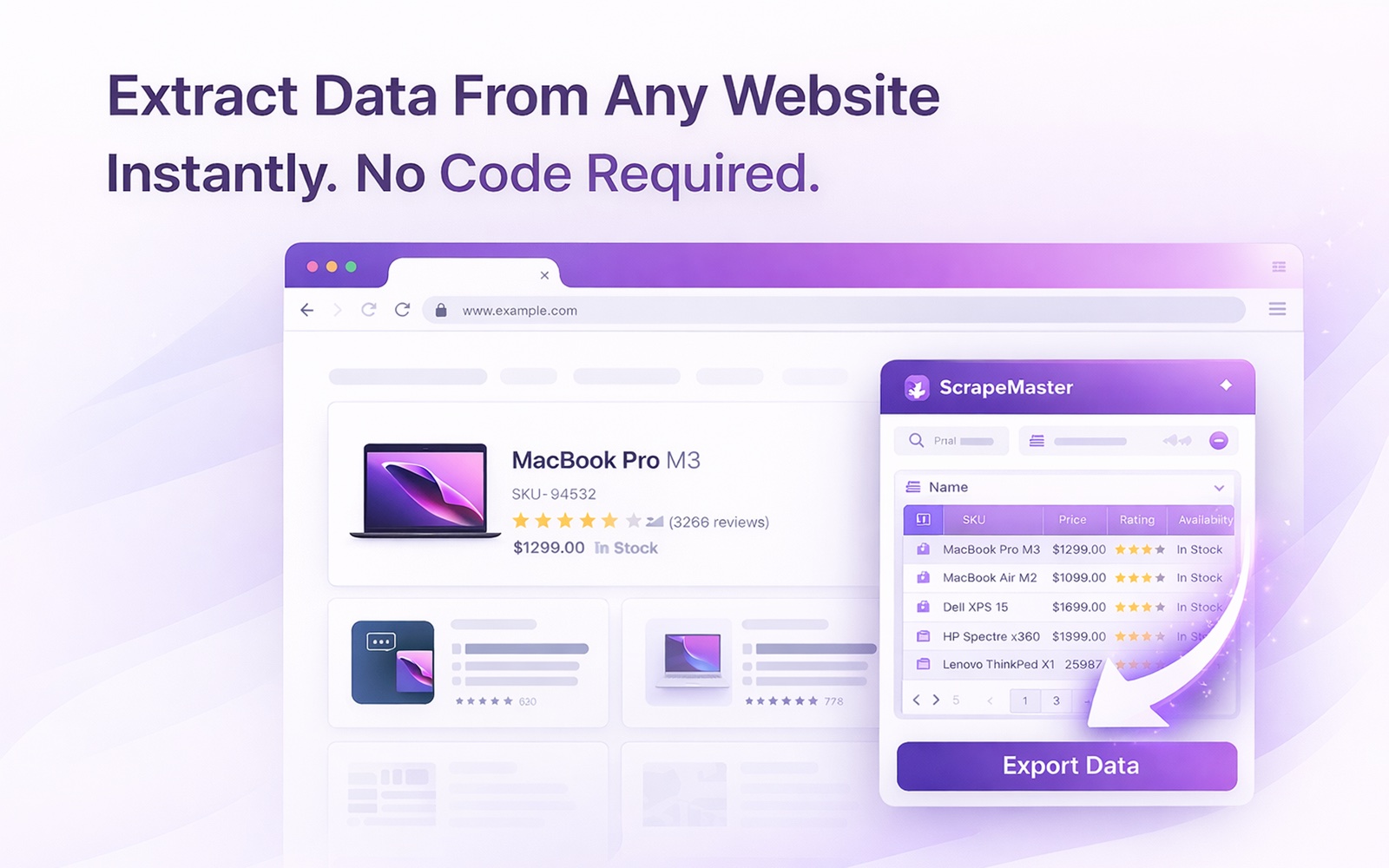
The specifics.
Concrete behaviour, not benefit-soup. If we say a feature works, you can test it in 30 seconds and prove us wrong.
AI-powered auto-detection
Click once and ScrapeMaster analyzes the page, detects repeating data patterns, and names columns intelligently — no setup, no selectors, no coding.
Full scraping pipeline
Handles next-page buttons, load-more buttons, numbered pagination, infinite scroll, and even follows links to detail pages for deeper data.
Export anywhere
Download as CSV, XLSX, or JSON. Or copy directly to clipboard for instant paste into Google Sheets, Excel, or your CRM.
Three steps, under ten seconds.
Click the icon
ScrapeMaster opens in a side panel and auto-detects data in 2–4 seconds. An editable table appears instantly.
Customize & expand
Rename columns, remove unwanted ones. Enable pagination or follow item links to scrape across multiple pages.
Export your data
Click Extract to pull all records with live progress, then download as CSV, XLSX, JSON, or copy for Google Sheets.
People who actually need this.
Sales & marketing
Extract competitor pricing, product listings, lead directories, and review data for analysis and outreach.
Recruiters & HR
Gather candidate lists from job boards — names, titles, companies, contact info — exported straight to your ATS.
Researchers & analysts
Collect structured data from any public source — real estate listings, academic papers, government records, news archives.
Things people ask before installing.
Honest answers — including where we say no. If something here doesn't answer your question, email actuallyusefulextensions@gmail.com.
Is ScrapeMaster really free?
Yes. No paid tier, no row limits, no credit card. You can extract as much data as your machine can hold.
Is web scraping legal?
Scraping publicly accessible data is generally legal in most jurisdictions, but specific use cases — re-publishing copyrighted content, violating a site's Terms of Service, scraping personal data subject to GDPR / CCPA — can raise legal issues. ScrapeMaster is a neutral tool; how you use it is your responsibility. We have several blog posts that go deeper on the legal landscape (LinkedIn, GDPR, CCPA, the EU AI Act).
Do I need to know CSS selectors or coding?
No. ScrapeMaster auto-detects repeating patterns on most pages within 2–4 seconds. You can rename columns, remove unwanted ones, and follow links to detail pages without writing a single selector.
Does it work on JavaScript-heavy sites (React, Vue, Angular)?
Yes. Because the extension runs inside your browser, it sees the page after JavaScript has rendered — exactly as you do. SPAs, infinite scrollers, and dynamic React components are all fair game.
Can it handle pagination and infinite scroll?
Yes. ScrapeMaster auto-detects Next-page buttons, Load-more buttons, numbered pagination, and infinite-scroll patterns. Extraction proceeds page by page with live progress shown in the side panel.
Can it follow links to detail pages and extract from those too?
Yes. The "Follow detail" feature opens each item's link in a background tab, extracts the additional fields you've defined, and merges them back into the main result table.
Will it get me blocked from sites?
ScrapeMaster uses your normal browser session and paces requests naturally. Heavy or rapid extraction on aggressive anti-bot sites (LinkedIn, Cloudflare-protected sites) can still trigger blocks; you can configure extraction delays to throttle as needed. The extension does not rotate proxies or fingerprints.
What export formats are supported?
CSV, XLSX (Excel-compatible), JSON, and direct clipboard for paste into Google Sheets, Excel, or any CRM. Exports save locally to your downloads folder.
Does my extracted data leave the browser?
No. Extracted records are stored locally in IndexedDB. The only network request is during auto-detect, when the page's HTML structure (not its content) is sent to our analysis API to suggest selectors. Your extracted data itself is never uploaded.
Can it bypass paywalls or login walls?
No. ScrapeMaster extracts data from pages you can already see in your browser. It does not bypass paywalls, defeat login requirements, or solve CAPTCHAs. If you can see it logged-in, ScrapeMaster can extract it.
Can I save my extraction configurations and reuse them later?
Yes. ScrapeMaster saves your column setup, pagination rules, and detail-follow configuration per domain. Visiting the same site later re-applies the saved configuration automatically.
Which browsers does it work on?
Chrome, Edge, Brave, Arc, and any Chromium-based browser. The extension uses Chrome's Side Panel API which is not available in Firefox or Safari.
Install ScrapeMaster.
Free forever. No account. Two clicks. Uninstall in two more if it doesn't help.
Add to Chrome →